Embedding v2: One Vector, Every Modality
2025 has been great for the embedding model space, with Google’s Gemini-Embedding-001-Model and Alibaba team releasing their own series of Qwen3 embedding models. Both models outperform their predecessors in quality on various tasks for text embedding generation.
We are also excited to enhance our capabilities. We have just launched a new version of our embedding model, offering much richer representations for different types of content and input languages.
Why a New Embedding Model?
Our first-generation embedding model (launched last year) introduced a unified vector space for text, images, PDFs, and audio in over 80 languages. It was built to address a key gap: most embeddings were text-only or English-only, making cross-modal, multilingual retrieval difficult. By supporting diverse formats with a single 768-dimensional representation, our v1 model enabled applications such as document and audio content retrieval, addressing the gap with a single query.
What changed?
Since then, the embedding landscape has evolved with larger models, and new techniques offer even better semantic capture and flexibility. With our latest model, you get:
- Richer High-Dimensional Vectors: Embedding v2 now outputs 4096-dimensional vectors (up from 768). This results in more accurate similarity searches and clustering, providing more relevant search results and better representation for data.
- Enhanced Multilingual & Cross-Modal Support: Our new model supports over 100+ languages and a variety of programming languages (up from 80). This means a single query vector can find matches in any language, e.g., a French audio clip could retrieve a relevant English paragraph.
- Instruction-Aware Customization: Embedding v2 is instruction-tuned, allowing it to better follow natural language guidance when generating embeddings. Greater customizability means you get embeddings aligned to your NLP task.
- Speaker Fingerprinting for Audio: You can now produce a unique speaker identity embedding from audio (The speaker fingerprint captures the speaker's voice traits, helping to identify or group speakers across clips).
Getting Started with Embedding v2
Embedding v2 is available now as part of our AI SDKs. It’s a drop-in upgrade; simply call the new /v2/embedding endpoint in our SDKs, and you’ll immediately start receiving the richer 4096-dim embeddings.
With Python:
With JavaScript:
We’ve ensured compatibility with popular vector databases and libraries, so you can index the following embeddings with Faiss, Pinecone, or others with ease
Be sure to check out our embedding v2 documentation for getting started with your choice of programming language and options for your use case. With this upgrade, our model equips you with state-of-the-art embeddings, so you can build AI applications that truly understand your data in all its forms.
Embedding v2 in Action
Let us ship a real-world product: An audio app powered by Embedding v2, with features:
- Lyric/quote search → return artist, song title, and exact timestamp.
- Voice match (“more from this voice”) via speaker fingerprints across tracks.
- Natural-language Q&A over your song/podcast library with timestamp citations.
- Batch ingest + retrieval for multiple audio files; ready for FAISS/Pinecone/Qdrant.
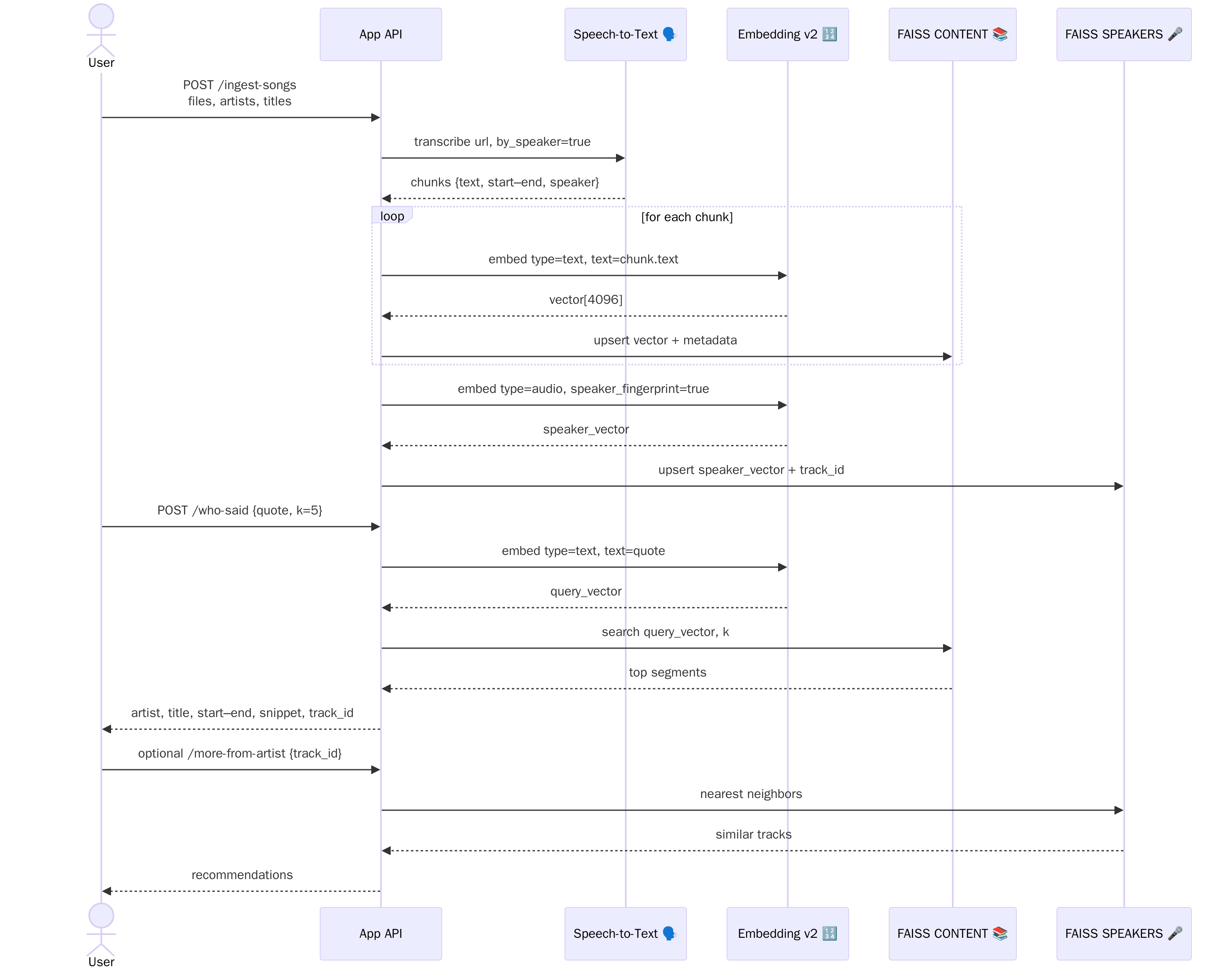
As shown in the sequence diagram above, we transcribe with timestamps, embed every lyric segment, and store a speaker fingerprint per track. Ask “who said guddi sikhran di jatt ni?” and you’ll get: Shubh, “Elevated” [00:18–00:24], plus an option to “search more songs by this voice.” The same pattern works for podcasts, meetings, and call logs while using Embedding v2.
You ingest a list of songs from various artists, say, Shubh (Punjabi, pa), Miki Matsubara (Japanese, ja), Adila Sedraïa, known professionally as Indila (French, fr), & Dhanda Nyoliwala (Haryanvi, bgc).
We will consider 4 distinct singles (audio clips) for this MVP, one from each artist named above:
- Elevated by Shubh (lyrics)
- 真夜中のドア/Stay With Me by Miki Matsubara (lyrics)
- Dernière Danse by Indila (lyrics)
- Russian Bandana by Dhanda Nyoliwala (lyrics)
We make the following requests in English to perform cross-lingual retrieval:
- Dhanda says he’s educated and must not be taken lightly.
Result:
- Indila says, “I dance with the wind and rain“
Result
- Miki Matsubara refers to a person wearing a gray jacket with a coffee stain.
Result
As we can see, English queries correctly matched lyrics in Punjabi (Gurmukhi), French, and Japanese, showing that our model can power retrieval by meaning, and not language or script, which is a huge win when dealing with multilingual data. The same pipeline works for podcasts, meetings, and call logs, multilingual queries over mixed audio libraries, with grounded answers and timestamp citations.
More importantly, you can replicate the example for PDFs, Images, and long texts with ease!
👥 Join the JigsawStack Community
Have questions or want to show off what you’ve built? Join the JigsawStack developer community on Discord and X/Twitter. Let’s build something amazing together!