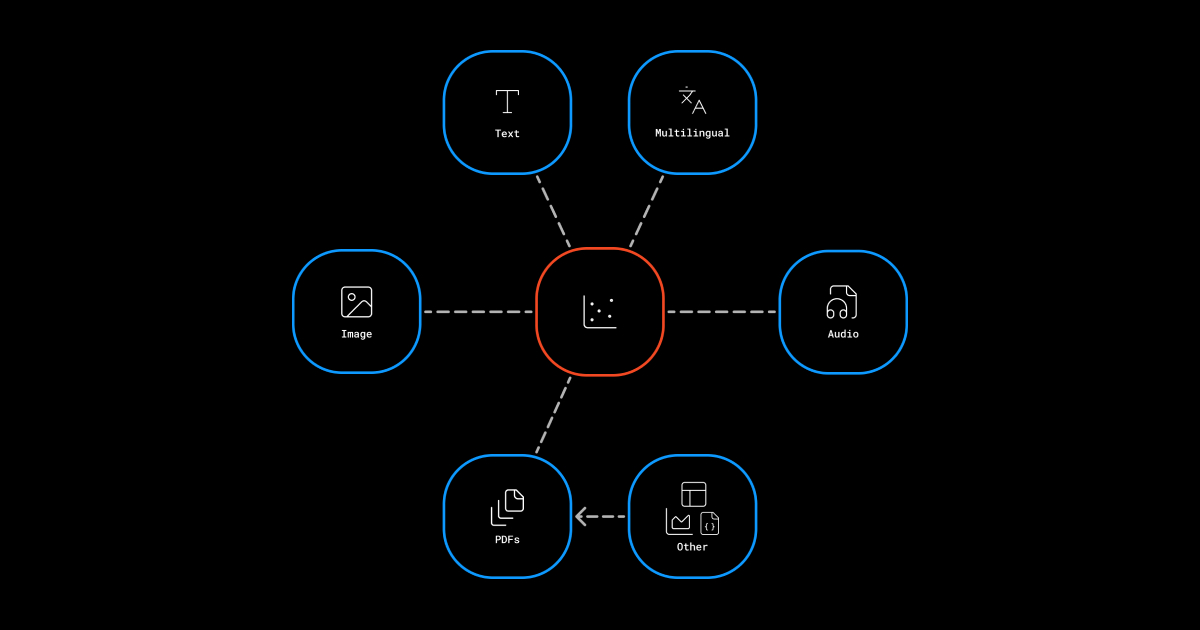
Introducing Multimodal Multilingual Embedding Model for Images, Audio and PDFs in Alpha
We launched our State-of-the-art embedding model that supports a wide range of document types including PDF, Images, Audio and more.
Quick Technical specs:
- Support inputs: text, image, pdf, audio
- Supports auto embedding chunking: yes
- 80+ languages
- Max input token: 514 (Auto chunking enabled for tokens larger than 514)
- Embedding dimension: 1024
- Average MRR 10: 70.5
- Average MAP (French): 72.14
- Average nDCG@10 (Code): 70.17
Every good AI application loves a good RAG!
Most RAG applications consist of two pieces: the vector database and the embedding model to generate the vector.
A scalable vector database seems pretty much like a solved problem with providers like Cloudflare, Supabase, Pinecone, and many many more.
Current problem
Embedding models, on the other hand, seem pretty limited compared to their LLM counterparts. OpenAI has one of the best LLMs in the world right now, with multimodal support for images and documents, but their embedding models only support a handful of languages and only text input while being pretty far behind open source models based on the MTEB ranking.
We tried looking and the closest solution we found was a OpenAI’s clip-vit-large-patch14 model which only supports text and image and was last updated many years ago with pretty bad retrieval
Most RAG applications we worked on had extensive requirements for image and PDF embeddings in multiple languages.
Enterprise RAG is a common use case with millions of documents in different formats, verticals like law and medicine, languages, and more.
Challenges
Multimodality sharing the same vector space
Getting multiple modalities to share the same vector space allowing for retrieval in any form such as image-to-image, audio-to-image, text-to-image and more.
Languages
Embedding models are small and inexpensive to operate, and many can run on CPUs. Embedding models need to catch up to LLMs and we believe they require similar GPU environments to run like LLMs. We built a larger sized model allowing for multilingual support over 80+ languages in all modalities.
Testing
The hardest challenge is testing. Embedding models are a pain to switch. Unlike LLMs you can’t switch a embedding model without re-embedding all the items on you database to the new model. Before launching our model into the wild for production use, we need your help to try it in real world applications to fix any edge cases, performance and DX.
Solution
We launched an embedding model that can generate vectors of 1024 for images, PDFs, audios and text in the same shared vector space with support for over 80+ languages.
Input token limit
Each embedding vector generated has a max token limit of 512 but the embedding API supports automatic chunking so if the token limit of a single file or text goes beyond 512, multiple embeddings of 512 will be generated. You can configure how the API should handle token overflow using the token_overflow_mode param.
Output Vector
Each embedding output generates a vector array of 1024 that can be stored in any vector database. In the situation of tokens going beyond the 512 input limit, multiple embedding vectors will be generated.
Supported formats
The model can handle files in pdf, image, text and audio formats. Any other file formats like word docx, charts, CSV can be converted to PDFs first then processed through the model to generate a vector. PDFs that contain images, urls and different format structures are also supported.
While the model supports video, we’ve disabled video support due to the high cost tied to it. Each frame of a video being processed it shoots the cost of significantly. We’re figuring out a way to reduce the cost. In the meantime you can embed the audio of any video.
Get started
Drop me a DM on x, discord or email me at yoeven@jigsawstack.com with your use case to get access. We’re happy to provide the embedding model free of charge to whoever has helped test the model in Alpha and for an additional 4 months free when the model is in production.
To learn more on how to get started with the API, check out this doc.
Here’s a quick example on how a request would look like in JS/TS 👇
Response example
👥 Join the JigsawStack Community
Have questions or want to show off what you’ve built? Join the JigsawStack developer community on Discord and X/Twitter. Let’s build something amazing together!