JigsawStack Mixture-Of-Agents (MoA): Outperform any single LLM and reduce cost with Prompt Engine
Applications that use LLMs typically tend to use more than one model or provider, depending on your use case.
This is because not all LLMs are built the same, while GPT-4o might be good at basic customer support chat, Claude 3.5 Sonnet would be good at understanding code.
More and more apps are using a Mixture of Agent orchestration to power their application, resulting in better consistency and quality of output with less breakage.
Some stats 👇
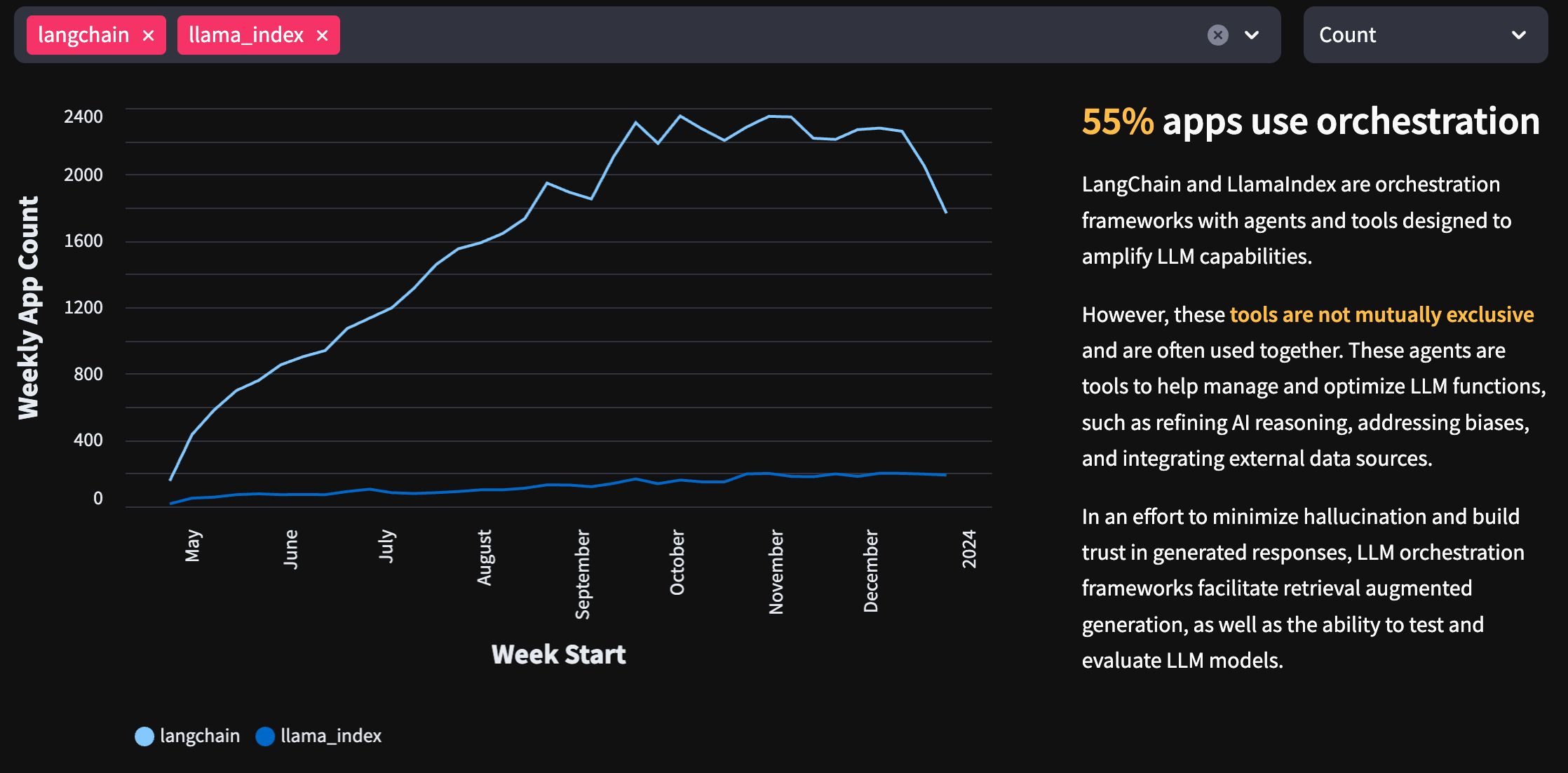
Ref: https://state-of-llm.streamlit.app/#top-orchestration-tools
Prompting is a pain in the ass, especially when moving between models while controlling cost or even switching models without breaking your entire code base.
Frameworks like LangChain make it way easier to add structure between LLMs, but that doesn't help with the quality of model response or picking a model that would make sense in balancing the cost to performance to quality ratio.
It gets more difficult when you want consistent JSON data or to reduce your cost with prompt caching.
There are just too many variables to think of...
We built Prompt Engine to solve this problem, so all you have to do is write a solid prompt for your use case, and the engine takes care of the rest.
Here's how it works 👇
Two parts make up the Prompt Engine, the first is creating the engine and storing it, and the second is executing it.
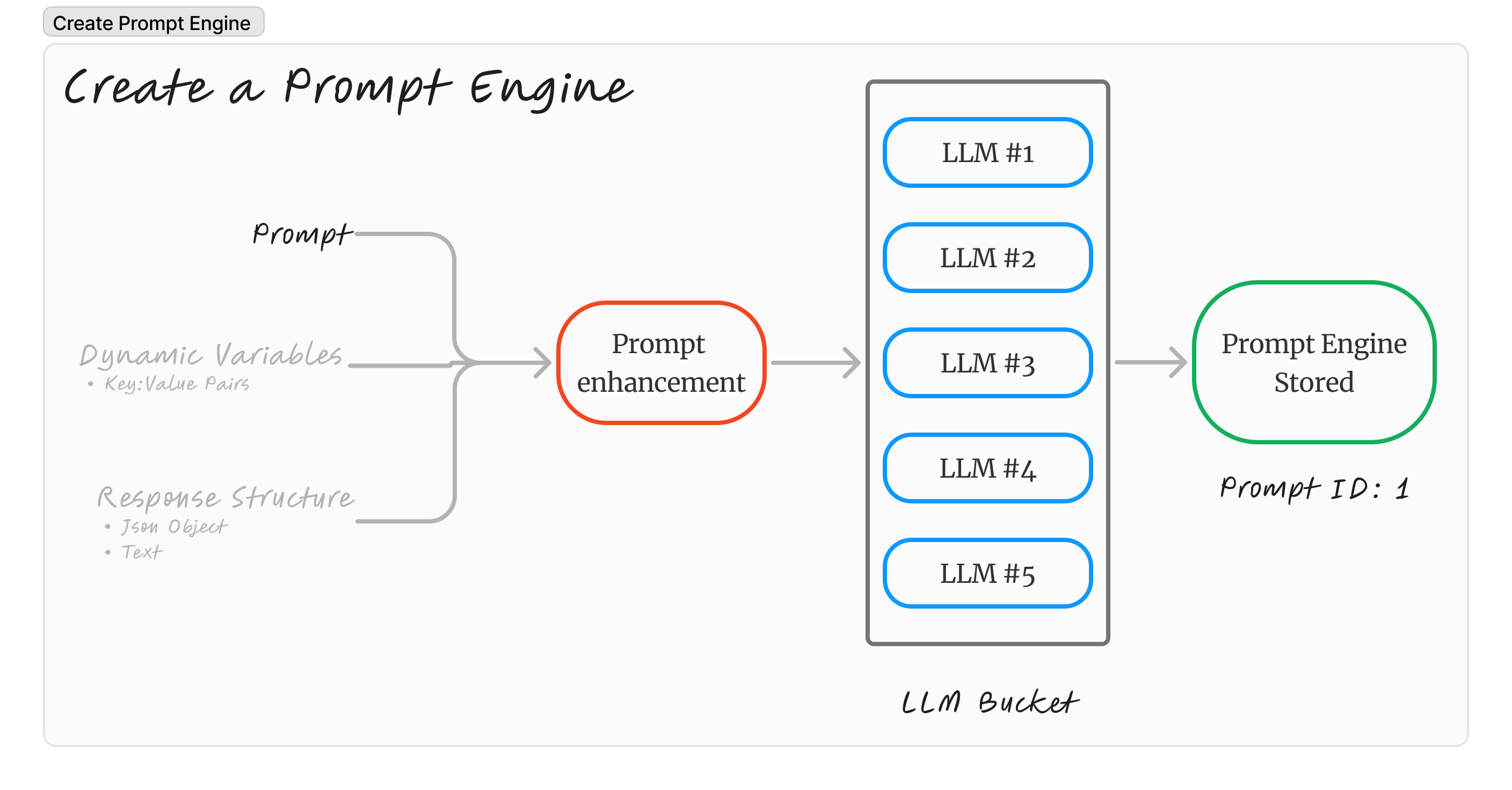
Creating a prompt engine takes in three things: the prompt, dynamic variables, and the output structure you expect every single time you run the prompt. The last two are optional.
The engine automatically enhances the initial prompt to improve accuracy, reduce token usage, and prevent output structure breakage.
Then, from a list of 50+ LLMs, 5 of the best LLMs that closest relate to the prompt are bucketed together.
This forms a single engine, which is represented by an ID.
Here's the code example of how you can create a Prompt Engine 👇
Now, for the fun part, running the engine.
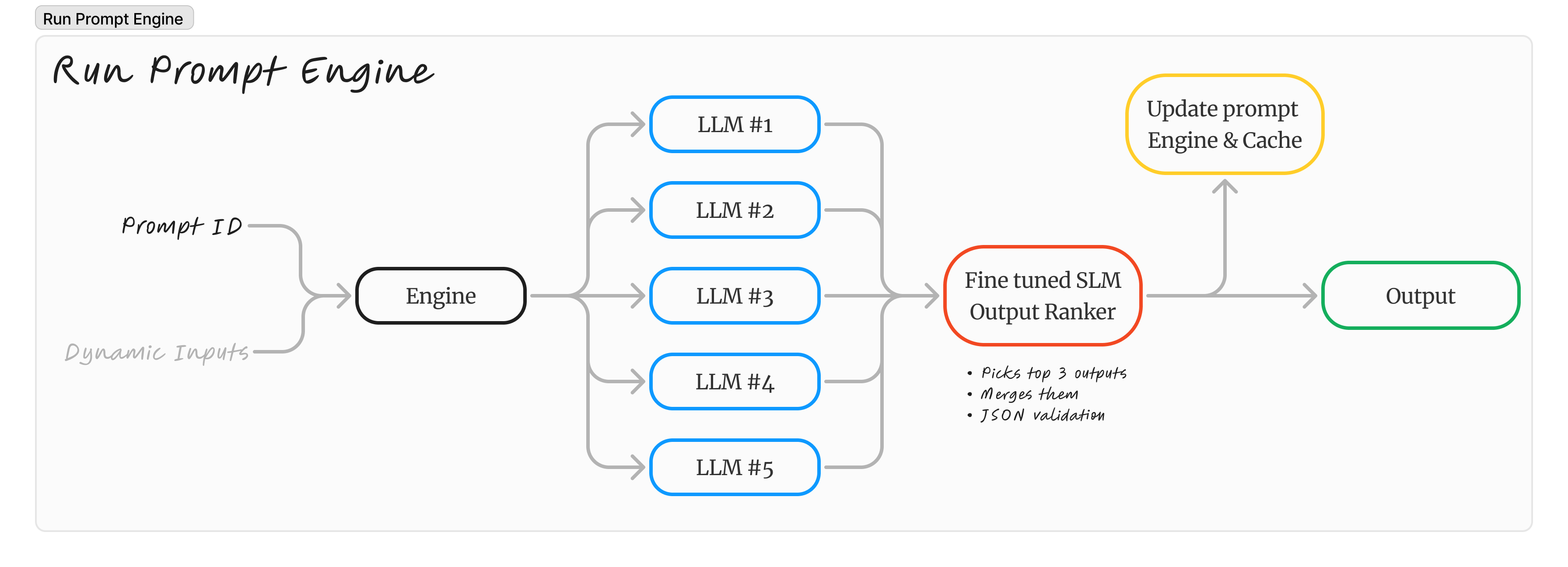
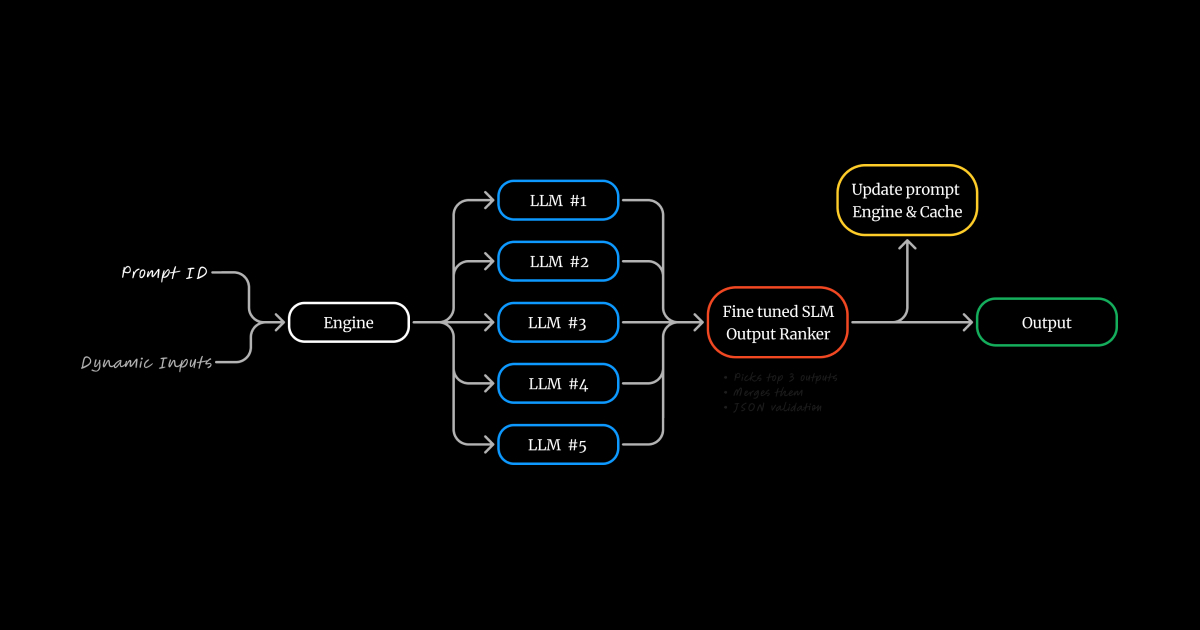
After creating a Prompt Engine, you'll get an ID that represents it, using that ID, you can run your engine and pass in any dynamic values defined earlier.
When running the prompt engine, the 5 LLMs that were initially bucketed together when creating the prompt will run in parallel.
Each output will be ranked from best to worst by a smaller model that's good at ranking and comparing outputs based on the initial prompt and the similarity of each output.
The top 2 to 3 outputs will be combined into a single output while maintaining the conditions you set in the return_prompt field.
Over time, as you run the engine, the bucket of LLMs gets reduced as the engine learns the common LLMs that tend to perform better with your prompt, leading to faster and higher quality outputs.
This significantly increases the quality and consistency of running prompts on LLMs while reducing hallucinations.
Each run gets cached, so running the same execution multiple times reduces cost and response time significantly.
Here's the code on how to run a Prompt Engine 👇
Want to run a Prompt without creating an engine first?
That's possible, check out the docs to learn more.
However, it isn't recommended. It might be a good way for you to quickly iterate on prompts and test, but the benefits of using the Prompt Engine get lost when you don't create and store the engine.
While the concept of how the Prompt Engine functions behind the scenes might be complex, JigsawStack has made it as simple as calling a function like any other LLM.
You can learn more here to get started with the SDK.
Check out one of the papers used as a reference.What's next?
The prompt engine models are consistently kept up to date with the latest models from providers like OpenAI, Anthropic, MistralAI, and even open-source models on Hugging Face that have commercially available licenses.
When upgrading to newer models, it can often break your code. Prompt Engine provides backward compatibility that gives you access to the best without breaking the old.
Join the JigsawStack Community
We invite you to join our growing community of developers on Discord and Twitter. Share your projects, ask questions, and collaborate with others who are just as passionate about innovation as you are.
Thank you for being a part of the JigsawStack journey. We can’t wait to see where you take it next!