
Use AI to summarize large content in your Postgres database
Video tutorial: https://youtu.be/3l3wRoLhb-o
Summarization might seem like a basic task but can be pretty challenging to extract quality and relevant chunks, rewrite it for larger content then to form a summarization. Summarizing a research paper requires understanding the context of the paper and how its formatted, while Youtube videos require us to understand where in the video is the main context. A 100,000 character long Wikipedia page with a wide range of different chapters and sections can provide a pretty inaccurate summary in most solutions.
LLMs might seem like a great way to achieve simplified summarizations but here are common issues we found with LLM summarizations:
- Small LLM context length which can’t handle large content in a single input
- Chunking large content decreases quality of summaries and may lose pieces of info depending on how chunking is done
- Context understanding of different types of documents and formats like a research paper vs a youtube video
- PDF support with images, links and text
- High hallucinations with larger and more complex content
- Low consistency running the summarization multiple times
We typically see tons of large content being stored in databases and we experience this as well. Having summarization built right into the database would be an awesome way to understand our data or even display to the user quickly. Here’s how we built summarization into our Supabase Postgres DB using JigsawStack AI Summarization.
We assume you have the following:
- A Supabase database or a Postgres DB
- A JigsawStack API key
Creating table
Example table we’ll be using:
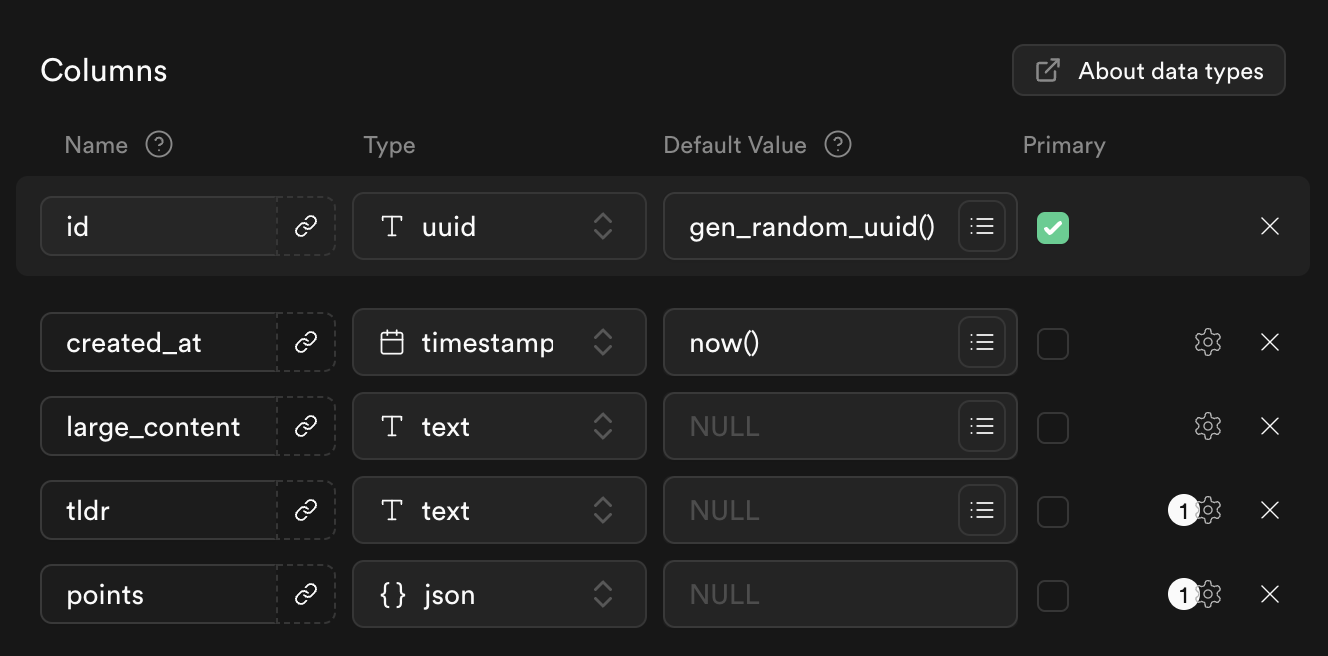
large_content will be used to store any large content text. tldr will be use to store the generated summary of the large content while the points column will be be summarization in point form. The large content can be in any document format from Markdown to HTML.
Creating a Postgres Function
Create a PostgreSQL function to handle the summarization task. This function will interact with the JigsawStack’s AI summarization API to summarize the text and update the relevant column in your table.
To set up the function:
- Navigate to the "Functions" tab.
- Click "Create new function" and give your function a descriptive name
- Copy and paste SQL code below into the “Definition” section
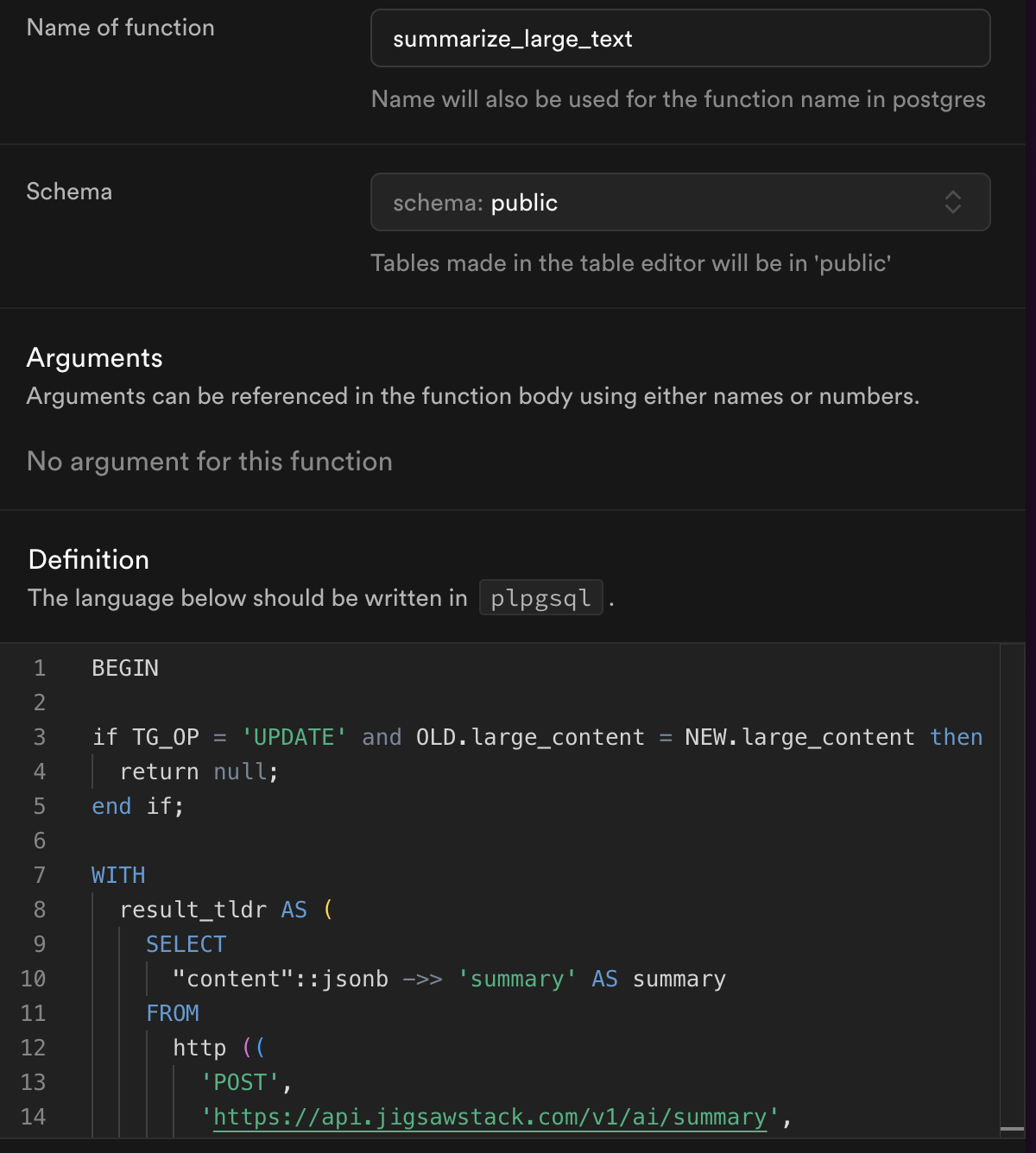
The SQL code does three things:
- Does nothing if
large_contentdon't change in update operations - Makes API requests to JigsawStack's AI summarization API twice, once for tldr and once for points
- Stores summarized text and points into the
tldrandpointscolumn respectively
This is a great starting point, but you might want to edit the code for the specific columns you want and your table schema definition.
Here is how your function should look like in the Supabase dashboard:
Setting up Postgres Triggers
Next, set up PostgreSQL triggers to automatically carry out the summarization whenever text is added or updated in the large_content column.
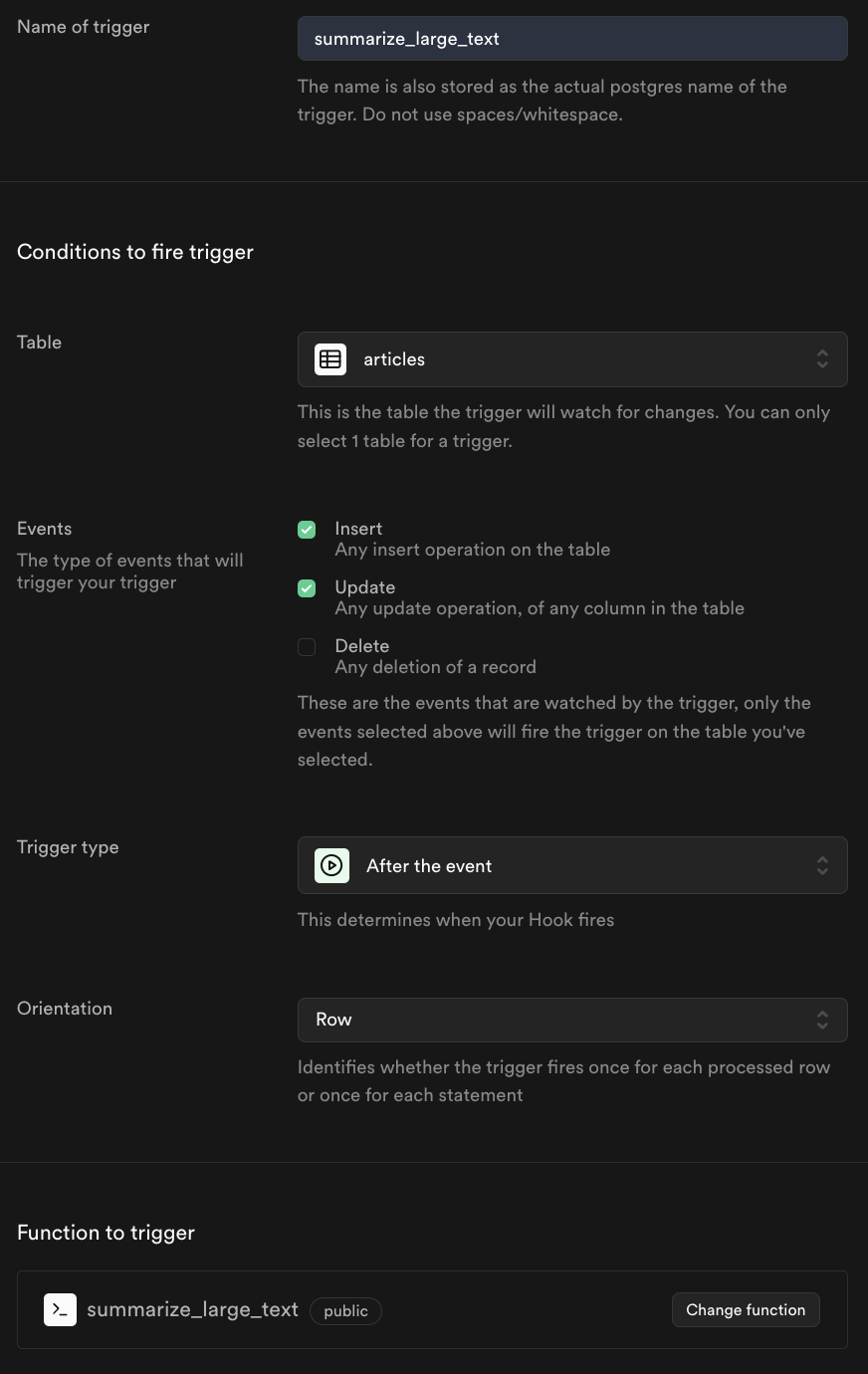
Head over to the trigger section, create a new trigger, and give it a name.
- Select the
articletable - Select
insert&updateoperations, which will only activate this trigger for that operation on thearticletable - Change the trigger type to
After the event, allowing for async operations - Change the orientation to
Row, allowing the trigger to run per row rather than a single statement, which could affect multiple tables - Create the trigger
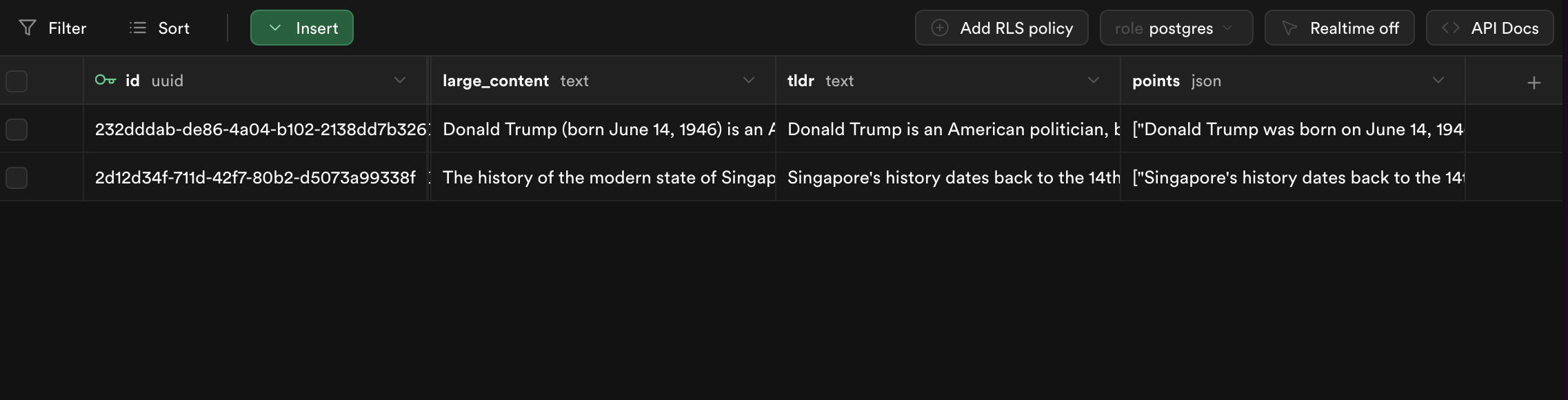
Try it out!
Head back to your table editor and update or create a new row with any large content. You’ll see the tldr and points column automatically getting generated with the summary.
Now you have built in summarization in your database and this can be applied in any Postgres DB.
You could upgrade this to handle PDF documents by passing the url of the PDF to the summarization API as well.
Common mistakes:
No errors were shown, and translation isn’t working
You might have forgotten to add a valid JigsawStack API key. You can also view all logs of each request made in the JigsawStack dashboard to understand the error.
Function throwing errors
Make sure the return type of the Postgres function is set to trigger and you’re mapping to the right columns.
👥 Join the JigsawStack Community
Have questions or want to show off what you’ve built? Join the JigsawStack developer community on Discord and Twitter. Let’s build something amazing together!