
OpenAI Audio STT vs JigsawStack STT
The past few weeks have been awesome in the AI Audio space, with a new ASR model from ElevenLabs, to the open source launch of Nvidia’s 1b Canary model.
OpenAI’s open-source model Whisper 3 large/turbo has been the gold standard for transcription which in our eyes remains pretty much undefeated when you compare the full feature set of languages, word level timestamps, and the ability the tune the model to add more languages and improve performance!
Many optimizations exist like faster whisper and our version Insanely Fast Whisper API which beats the base Whisper 3 & 2 provided by OpenAI through their API way out of the park.
OpenAI launched a closed-source model gpt-4o-transcribe that claims to be the “next-generation” of audio models, outperforming the best in the market by benchmarking themselves against Whisper 3, Gemini 2 and Nova.
What is Speech-to-Text/ ASR / Transcription? It’s a type of model that takes in an audio file of a speaker or multiple speakers and transcribes that into text. Some basic features all good Transcription models should have:
- Time stamps (Either word-level or sentence-level)
- Speaker recognition
- Large files & long audio support
- Blazing fast speeds for short audio (Real-time use case)
- Multilingual support & Translation
- High accuracy (WER)
We’ll be comparing OpenAI gpt-4o-transcribe against JigsawStack Speech-to-text in a series of real-world examples.
Sneak peek if you can’t wait 👇
| OpenAI gpt-4o-transcribe | JigsawStack Speech-to-text | |
|---|---|---|
| ⏳ Timestamps | No support was found on their docs. ❌ | Sentence level timestamp by default and speaker level timestamp available. ✅ |
| 💬 Speaker recognition | No support was found on their docs. ❌ | Speaker recognition through diarization is available with timestamp support per speaker. Up to 50 speakers supported. ✅ |
| ⛰️ Large file & long audio support | Supported up to 25 MB file size and 25 mins of audio per request. ❌ | Supports up to 100 MB file size and 4 hours of audio per request. ✅ |
| ⚡ Performance | Almost ~2.4x slower than JigsawStack ❌ | ~2.4x faster transcription on all audio lengths while providing more data like timestamps ✅ |
| 🌍 Multilingual support | Great support for transcribing most popular languages ✅ | JigsawStack came in close second for Native multilingual transcription ◐✅ |
| 🔄 Translation | No support was found on their docs ❌ | Built it translation support with over 100+ languages ✅ |
| 📝 Accuracy | No exact WER data but got a 93% accurate transcription on our real-world test. ❌ | Got 97% accurate transcription on real-world test. ✅ |
| 👯♀️ Team Size | ~5,300 people working at OpenAI | 3 people working at JigsawStack |
Here’s the simple JS/TS script we’re gonna use to test everything
Timestamps
5 seconds Short Audio Timestamp Example
OpenAI’s Transcription
JigsawStack’s Transcription
Both gave 100% accurate results, however OpenAI currently doesn’t support timestamps.
4 minutes Audio Timestamp
OpenAI’s Transcription
JigsawStack’s Transcription
JigsawStack managed to accurately break down each sentence with timestamps while OpenAI provided a large chunk of text with no breakdown.
Recognizing different speakers with diarization
Random YC interview video from Youtube
OpenAI’s Transcription
JigsawStack’s Transcription
We’ll have to update the above test script to add by_speaker: true to the JigsawStack SDK to generate speaker tags. It should look something like this.
Result
OpenAI latest transcription model doesn’t have support for speaker recognition and tagging which makes up a huge chunk of audio transcription use cases. JigsawStack easily transcribed the above audio both by timestamp and by speaker tags under 15 seconds.
We’re pushing a huge update in the coming week that will improve the speaker recognition output performance by 10x for longer audios while increasing quality
Large files & long audio support
1hr 35mins audio with multiple speakers
OpenAI’s Transcription
JigsawStack’s Transcription
Too large for this blog, view full output here: https://gist.github.com/yoeven/a2c1c6eae388e34c350ffe1f407f8af5
OpenAI doesn’t support large files above 25 MB or audio durations above 25 minutes. JigsawStack transcribe a 32 MB file that’s over 1hr 35mins long under 30 seconds at high accuracy with a sentence by sentence timestamp breakdown.
Performance & Realtime Speed
5 seconds Short Audio Example
Same audio file we used at the start for the timestamp example.
OpenAI and JigsawStack Results (Lower is better)
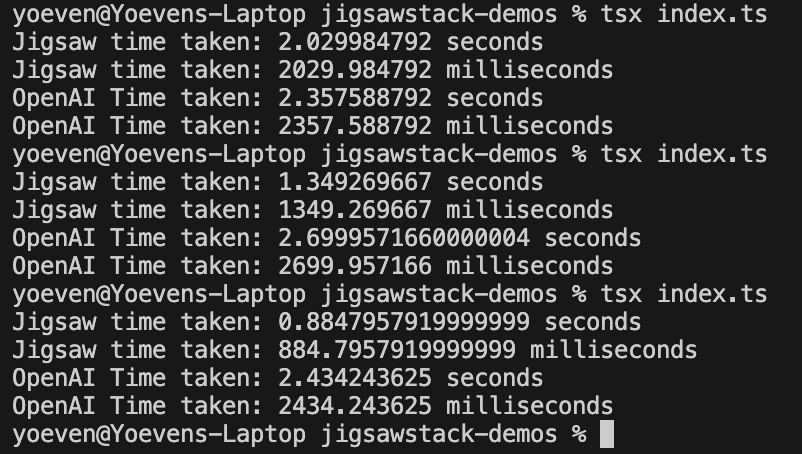
We ran 3 runs on the same audio file, initially on the first run, OpenAI was close to JigsawStack’s performance but still slower by a 300ms. By the second and third run, OpenAI’s model slowed down significantly taking almost double the time.
Having a great model is not enough, having the right infrastructure set up to run it at scale is equally as important. This is why we train our models specific to the infra we’re building on.
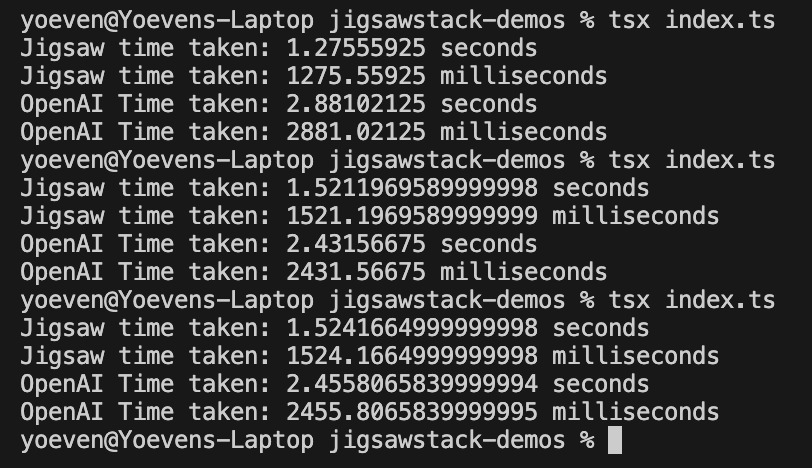
3 seconds Short Audio Example
OpenAI and JigsawStack Results (Lower is better)
OpenAI’s Transcription
JigsawStack’s Transcription
Once again we see JigsawStack outperforming OpenAI’s latest & best speech-to-text model with double the performance. You can also see that OpenAI’s model wrongly transcribed the audio with only one oh no but there was two.
4 minutes Audio Timestamp
Same audio file we used at the start for the timestamp example.
OpenAI and JigsawStack Results (Lower is better)
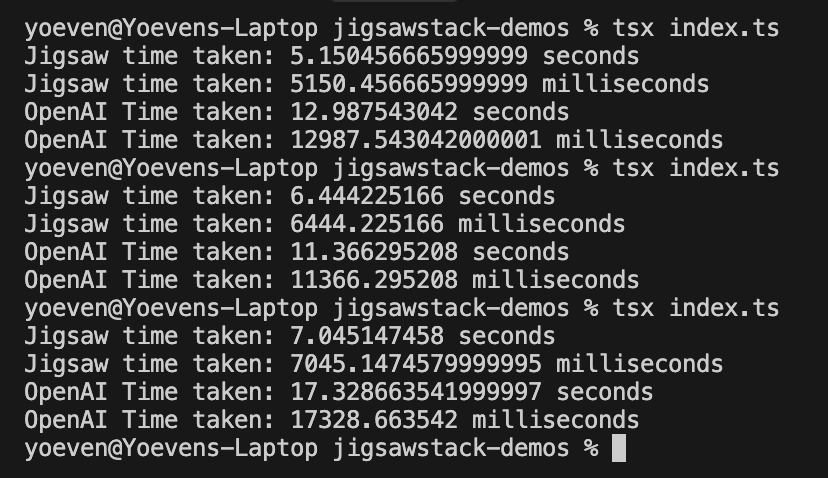
JigsawStack outperforms OpenAI even in longer audio by 2.4x faster performance while being more accurate!
Multilingual & Translation
Hindi Audio Transcribe Example
We’ll add a language config on both OpenAI’s and JigsawStack’s SDKs to let it know the audio is in Hindi. It should look something like this.
OpenAI’s Transcription
JigsawStack’s Transcription
OpenAI had an higher accuracy for native Hindi transcription compared to JigsawStack which was a close second.
Hindi Audio Translate Example
We’ll use the same Hindi audio sample
We’ll add a language config on both OpenAI’s and JigsawStack’s SDKs to let it know to translate the audio to English. It should look something like this:
OpenAI’s Transcription
JigsawStack’s Transcription
OpenAI’s latest model has no support for translation or prompting which prevents the translation setting from working. On the other hand, JigsawStack natively support translation into most languages. You can find all supported languages on our docs here.
Accuracy Word Error Rate (WER)
Noisy Audio and background voices
OpenAI’s Result
JigsawStack’s Result
While OpenAI claimed to have a lower WER than the rest, in this example of a noisy example, JigsawStack got 100% accurate results while OpenAI has missing and inaccurate transcription making it only 94% accurate in this example.
JigsawStack Text (97% accurate)
You are wearing the target speech steering system. You can click the button on the right and then look at me for a few seconds. Now when you are looking at me, the system will register my voice and enroll it. Now you can take a walk. So now the system has an enrollment of my voice, it can extract__, it can focus on only my voice while ignoring all the interfering sounds in the environment. So we introduced this system called click on CD, where we__, like suppose we're in a scenario like this where you're trying to hear my voice when someone else is trying to speak, then You can just look at my, you can look at me for a few seconds, get some noisy example of my voice, and then you can separate out or filter out my voice only from everybody else's.
- Guessed the wrong name “click on CD” when it’s suppose to be “Look Once to Hear”
OpenAI’s text (93% accurate)
Hey, you're wearing the target speech hearing system. You can click the button on the right and then look at me for a few seconds. Now when you're looking at me, the system will register my voice and enroll it. Now you can take a walk. So now the system has an enrollment of my voice, it can focus on only my voice while ignoring all the interfering sounds in the environment. So we introduced this system called Sequence in Use, where suppose we're in a scenario like this, where you're trying to hear my voice when someone else is trying to speak, then you can just look at me for a few seconds, get some noisy example of my voice, and then you can separate out or filter out my voice only from everyone else's.
- “it can extract” is missing from OpenAI’s text
- Guessed the wrong name “Sequence” when it’s suppose to be “Look Once to Hear”
- missing “we” and “like”
Conclusion
We’re huge fans of the work being done at OpenAI, especially the open source work! This article wouldn’t be possible without Whisper 3. The base model we optimized and trained to get the output you see here!
In all the above tests we used JigsawStack’s transcription model and OpenAI’s latest transcription model. You can run all tests yourself using these APIs and the script provided at the start of this article.
Overall JigsawStack outperformance OpenAI’s best in class speech to text model, in performance, accuracy, features and more!
| OpenAI gpt-4o-transcribe | JigsawStack Speech-to-text | |
|---|---|---|
| ⏳ Timestamps | No support was found on their docs. ❌ | Sentence level timestamp by default and speaker level timestamp available. ✅ |
| 💬 Speaker recognition | No support was found on their docs. ❌ | Speaker recognition through diarization is available with timestamp support per speaker. Up to 50 speakers supported. ✅ |
| ⛰️ Large file & long audio support | Supported up to 25 MB file size and 25 mins of audio per request. ❌ | Supports up to 100 MB file size and 4 hours of audio per request. ✅ |
| ⚡ Performance | Almost ~2.4x slower than JigsawStack ❌ | ~2.4x faster transcription on all audio lengths while providing more data like timestamps ✅ |
| 🌍 Multilingual support | Great support for transcribing most popular languages ✅ | JigsawStack came in close second for Native multilingual transcription ◐✅ |
| 🔄 Translation | No support was found on their docs ❌ | Built it translation support with over 100+ languages ✅ |
| 📝 Accuracy | No exact WER data but got a 93% accurate transcription on our real-world test. ❌ | Got 97% accurate transcription on real-world test. ✅ |
| 👯♀️ Team Size | ~5,300 people working at OpenAI | 3 people working at JigsawStack |
How to get started with JigsawStack Speech-to-Text?
Our goal at JigsawStack is to build small focused models that are specialized at doing one thing very well while making it accessible with great DX!
Typescript/Javascript example
Python
What about Text-to-Speech (TTS)?
We want to go deep dive into TTS so we’re writing a separate article breaking down the comparison. You can try it out here in the mean time. Here’s a small sneak peak on how it sounds 👇
Join us on Discord or follow us on X to keep up to date with our future launches and the TTS comparison