
Beyond the Box: The Future of Object Detection
It’s 2025, and object detection is a solved problem. Or is it?
Object detection is like giving machines eyes. It’s the computer vision task of finding and localizing people, cars, cups, and other objects in images or videos. Unlike plain image classification (which simply states “this is a cat”), object detection draws little boxes around objects.
At JigsawStack, we’ve been developing the best small object detection and grounding model available, built to handle not just detection, but also spatial grounding, segmentation, and even UI element detection for computer use. One model. All the sauce.
In a world where browser agents now see, click, and reason, object detection is the backbone behind not just smart cameras, but UI automation, accessibility tech, and even creative tools. Computer use itself has exploded in the last three years, and under the hood, it’s all powered by the same core: visual grounding for object detection.
Vision-Language Models in Detection
Historically, object detection has been specialized for specific industries, factories, construction sites, and even medical research. But at JigsawStack, we asked: Can we build a single, small, general-purpose model that handles everything from segmenting any real-world object to grounding UI buttons?
Early VLMs were used for classification or captioning, but now developers are adapting them to draw boxes. For example, CLIP-inspired methods (such as GLIP, Grounding DINO, and OWL-ViT) transform language supervision into object localization. These models let you pose queries like “Where is the apple?” and get back bounding boxes or masks. Grounding DINO and OWL-ViT are prime examples: they leverage text prompts to find novel objects at first attempt (zero-shot).
Here’s the state of object detection in 2025:
- You can now just type “find the red mug” and open-vocabulary detectors like Grounding DINO 1.5 will box it, even if “red mug” was never in the training set.
- Meta’s shiny SAM 2.1 goes beyond boxes by carving out pixel-perfect cut-outs of any object with one click or prompt.
- Chatty AIs such as GPT-4o can reply with bounding-box coordinates straight from plain-English questions.
- Edge-tuned versions like Grounding DINO 1.5 Edge now run on phones and drones, so object detection works offline in real time.
- Devs are chaining detectors to segmenters, think Grounded SAM 2 for one-click “find-and-mask” pipelines in production APIs.
Examples: What can our model do?
- Basic Object Detection: detects all visible objects.

- Prompt-based Object Detection: Find anything you can describe—“find the red mug,” “show me cranes,” or even “utensils which can be used for frying”. Take a look at what our model detects for the prompt “four-legged fren <3“

- Computer Use: understands and localizes user interface elements (e.g., buttons, sliders) for computer use. Following is a screenshot for detections for VScode with a chat input pop-up for local computer use.
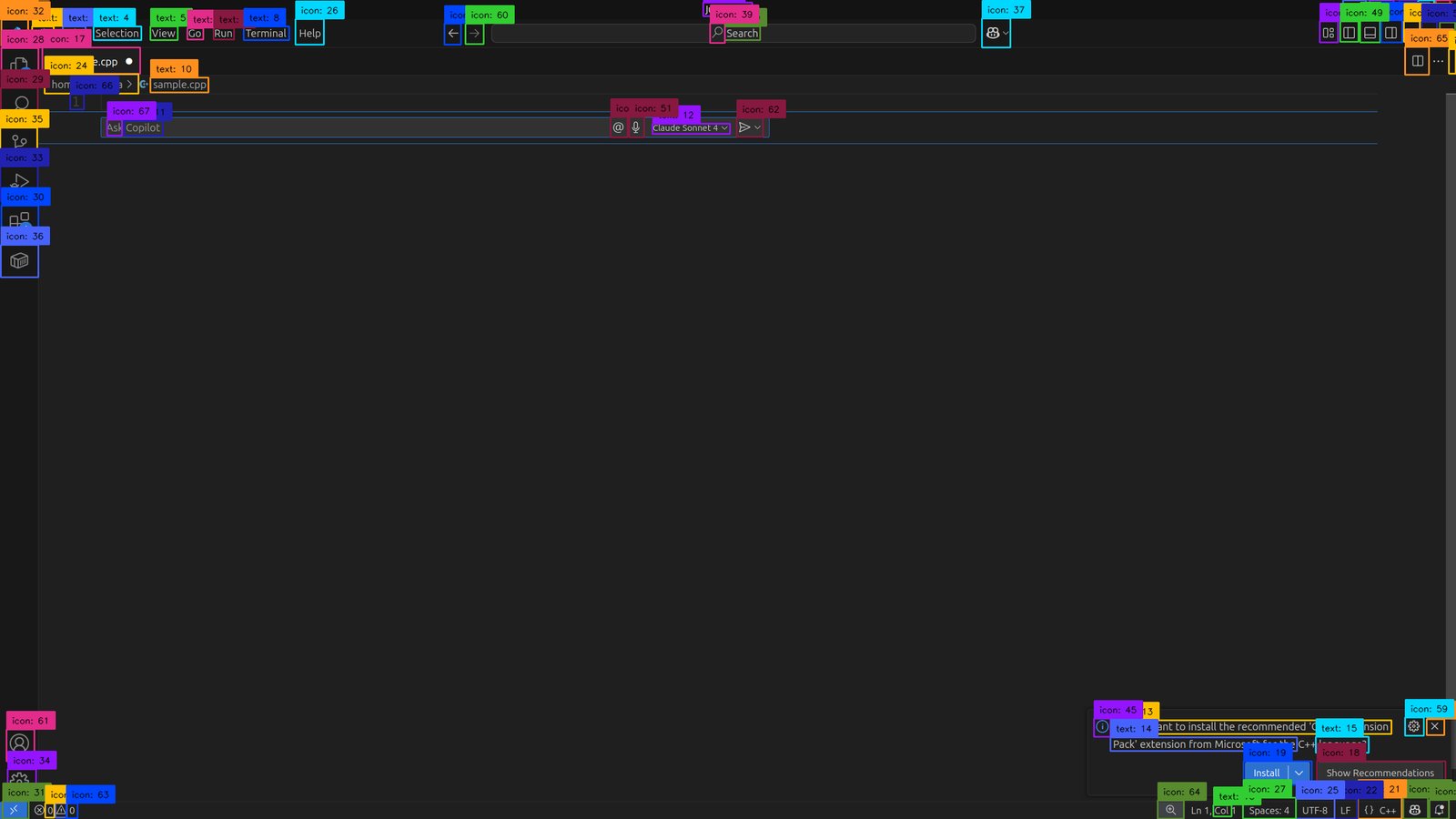
- Browser Automation: Automate website navigation by GUI element grounding. With prompting e.g. “search field“, “give me the search button“, e.t.c.
Can JigsawStack see an image differently?
Totally! Because we built the model around phenomenon vision-language alignment instead of just cranking up the model size. Alignment means the pixel-side encoder and the text-side encoder learn to land in the same semantic space, so “oplayer” and the blob of pixels that is a player overlap on the inside. Do that well and you get:
- Generalisation on tap – snap to the right region even if they never showed up in training.
- Promptable precision – ask for a UI button, a road sign, or a corgi wearing goggles, and the model adaptively tightens its boxes or masks.
- One-shot spatial reasoning – verbs like left of, under, right, or next to that pillar come baked in, no extra heads required.
Small model, aligned brains, fresh set of eyes for every prompt. Let’s take a look to see if our model can point to the right objects ;)
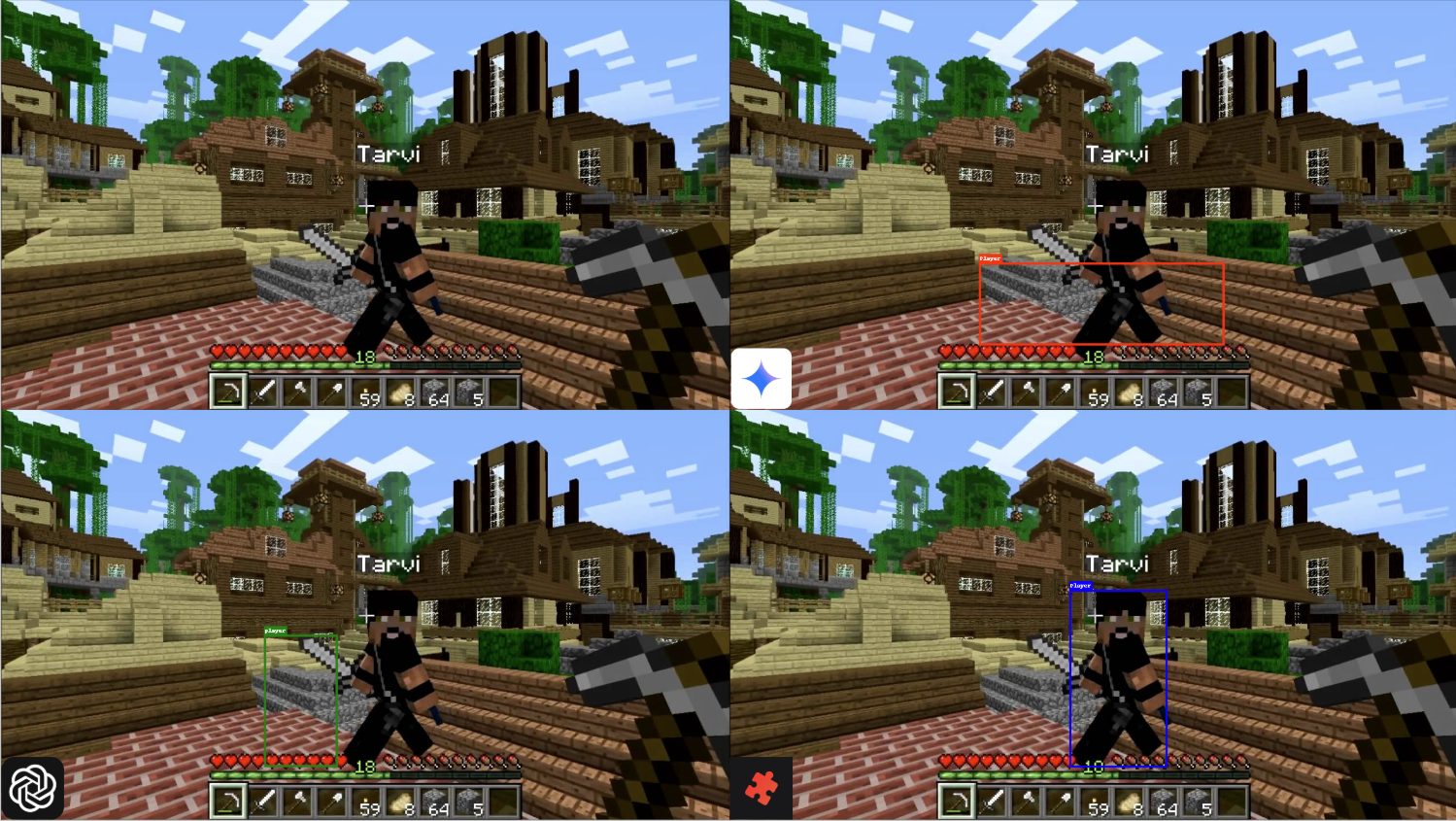
Grid: Comparing Gemini-2.5-Pro (top-right), GPT-4.1 (bottom-left), & JigsawStack-ObjectDetection (bottom-right) on Minecraft (GUI-grounding), with prompt “player“

Grid: Comparing Gemini-2.5-Pro (top-right), GPT-4.1 (bottom-left), & JigsawStack-Object Detection (bottom-right) for object_detection with prompt “crane“
Let’s take a look at segmentation ability as well!

Image: JigsawStack-Object Detection for Segmentation, with prompt “helmets“

Image: fal-ai/SAM-evf for Segmentation, with prompt “helmets“
Quick Start with JigsawStack Object Detection
Getting started with our object detection model is incredibly straightforward. Whether you're developing a web or mobile app, our JavaScript and Python SDKs make the process seamless. With just a few lines of code, you can tap into JigsawStack's capabilities to detect, segment, and annotate objects in images, adding a layer of intelligence and interactivity to your application. Ready to dive in? Let's explore how you can set up and make your first call using our SDKs

Image: Golden Gate Bridge in San Francisco
Let’s start by setting up JigsawStack SDK,
Make your first call with ease through our JS and Python SDKs
Similarly, in Python, you can use the object detection service as follows:
And voila!
Here's the annotated image showcasing our model's ability to detect, segment, label, and annotate.

Image__: Result from JigsawStack-Object Detection
Play With JigsawStack Object Detection
Users can also pass in natural language prompts to ground objects based on the intent & visual context in the scene.
Consider the following example:

Our model detects:

Image__: Result from JigsawStack-Object Detection for user query “Objects that can be used to illuminate the room.“
Our approach to generalizing object detection and segmentation is transforming the way developers integrate visual intelligence into their applications. With our user-friendly SDKs and powerful vision-language alignment, you can effortlessly enhance your projects with cutting-edge technology. Whether you're working on a web or mobile app, JigsawStack provides the tools you need to bring your ideas to life. And we’re excited to see devs build with our smoll models capable of big impact!
👥 Join the JigsawStack Community
Have questions or want to show off what you’ve built? Join the JigsawStack developer community on Discord and X/Twitter. Let’s build something amazing together!