
Context Engineering: Yet Another Branch of "Engineering" Involving Language Models
Have we just rebranded prompt engineering? Like Apple did with “Glass“? Well, turns out that there is more to context-engineering than writing lengthy prompts.
If prompt engineering was about cleverly wording a single query to coax a good answer, context engineering is about orchestrating everything the AI needs around that query. Ideally, it allows us to address the shortcomings of prompt engineering for tasks that require multi-step reasoning or developing answers scattered within various knowledge bases.
From Prompt Engineering to Context Engineering
Prompts by themselves couldn’t provide memory of past interactions implicitly, up-to-date knowledge, or ensure the AI stayed on track over a long dialogue. Developers realized that many failures of LLMs (like irrelevant or made-up answers) weren’t due to the model being “bad” – it was because the system around the model didn’t give it the right context or support. In other words, a clever prompt means little if it’s buried in a sea of irrelevant text or if the model lacks crucial information.
This insight gave rise to context engineering. Instead of focusing only on the prompt itself, context engineering is about designing the entire environment in which the AI operates. One article succinctly defines it as “structuring everything an LLM needs to complete a task successfully.” As Andrej Karpathy described, if prompt engineering is like writing a single sentence, context engineering is like writing an entire screenplay for the AI. You’re not just giving an instruction, you’re providing background, setting the scene, and making sure the AI has all the pieces to “get it right.”
Building Blocks of Context Engineering
So, what exactly goes into the engineering context for a language model? It typically means managing and curating a variety of inputs around the prompt, such as:
- Conversation history and memory: Supplying relevant parts of prior chats or interactions so the model “remembers” important details.
- Relevant documents or data: Fetching knowledge from databases, files, or the web (often via retrieval techniques) to inform the answer.
- Structured instructions and context format: Framing information in a model-friendly way – for example, providing clear system instructions, or formatting data as tables or JSON if needed. Tools and actions: Allowing the model to invoke external tools or APIs (like calculators, web search, or code execution) and feeding those results into the context
- Tools and actions: Allowing the model to invoke external tools or APIs (like calculators, web search, or code execution) and feeding those results into the context.
In essence, context engineering is about filling the model’s context window (its working memory) with the right information, at the right time, in the right format. A lot of devs would argue that they’ve been doing this since day one, and now we’ve just labeled it.
Why Context Engineering is the Latest Trend?
The move toward context engineering comes from practical necessity. As developers built more “industrial-strength” LLM applications. Context engineering delivers that by reducing guesswork. Instead of hoping a single prompt will make a model magically know about your 100-page knowledge base, you feed the knowledge base (or its highlights) into the model’s context.
Instead of the model forgetting what was said 10 messages ago, you make sure to persist important history forward. Rather than just asking the LLM to perform a task blindly, you might give it step-by-step context or even let it call functions and then supply the results back into the conversation.
Key factors that are driving this trend:
- New tooling libraries and frameworks, pushing what’s possible in agents’ memory.
- Growing context windows allow devs to feed whole documents whenever needed, thus achieving a better utilization of the language model’s context window.
- It’s a system, not a sentence! A well-engineered context means devs don’t have to tailor prompts for every scenario.
Context engineering treats AI behavior as a systems design problem. Rather than solely relying on clever wording, it emphasizes architecting the information flow around the model.
What Do the Numbers Say About Context Engineering?
There is growing evidence that better results and stability can be achieved by setting the context for a language model, in contrast to a simple prompt.
A Databricks study evaluated retrieval‐augmented generation (RAG) using long‑context models, such as GPT-4‑turbo (128k tokens) and Claude 2 (200k tokens). They found that providing more retrieved documents increases answer quality, especially on QA tasks across corporate and financial domains.
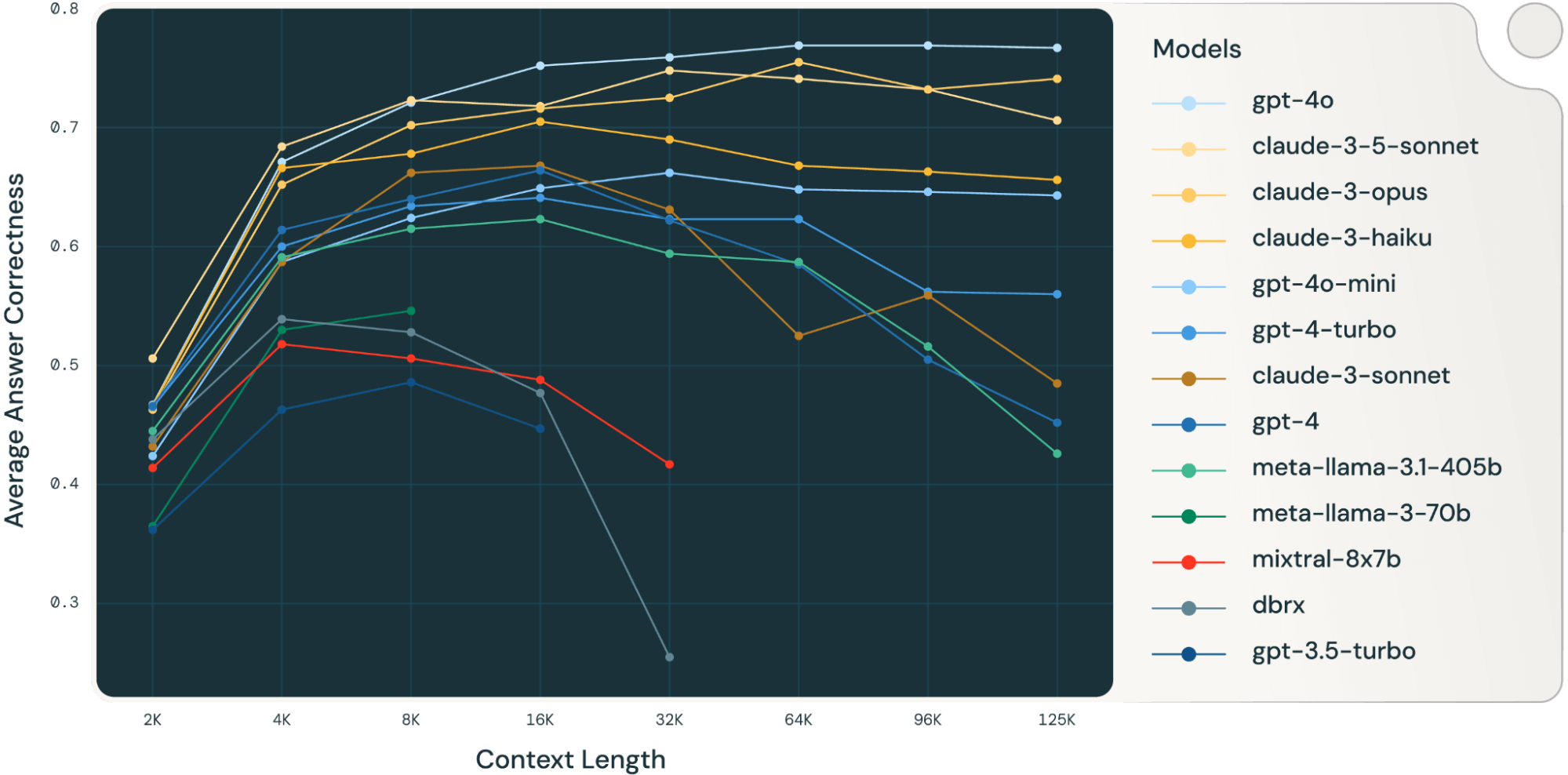
However, models struggle if the context is too long (“lost in the middle”), so properly chunking and curating context is critical [1].
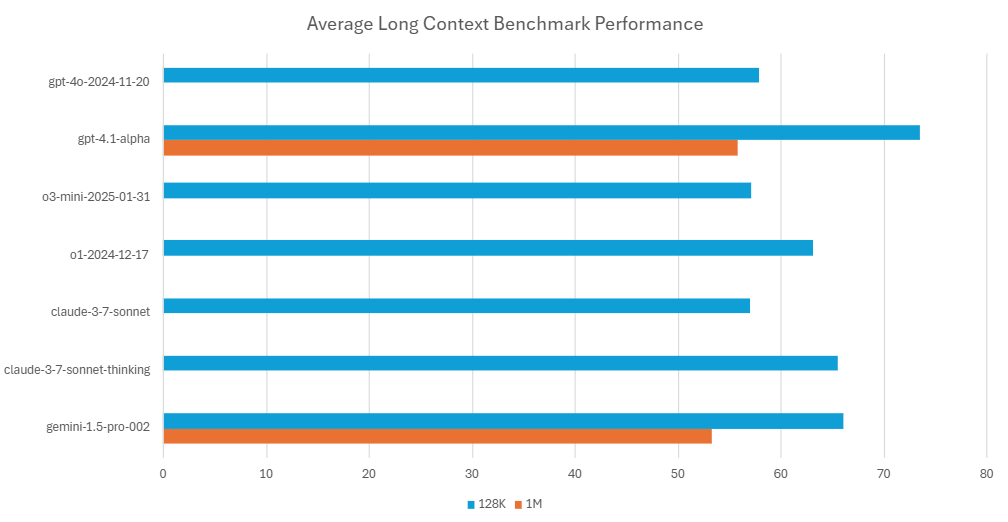
Thomson Reuters benchmarked long‑context LLMs (up to 1 M tokens) vs retrieval-based. Their internal tests revealed that feeding full legal documents into the LLM outperformed RAG in most document-based reasoning tasks. LC models handled multi-hop reasoning more effectively than RAG approaches [2].
Additionally, research from Nvidia presented at ICLR 2025 showed:
- Best results come from combining retrieval and long-context capabilities.
- A LLaMA2‑70B with 32k context + retrieval matched or surpassed GPT‑3.5‑turbo‑16k and Davinci003.
- The LC+RAG combo outperformed LC-only baselines, showing clear synergy [3].
Final Takeaway
With growing excitement around context setting (engineering), and quantitative proofs backing this excitement within the community, it proves that it isn’t hype but is empirically superior for domain-specific knowledge work.
Language Models with large context windows shine when their context window utilization is higher, with targeted retrieval, where dump=everything strategies falter. Thus, backing the sentiment that feeding the model the right context, even via retrieval pipelines or using very long context data inputs, yields measurable gains over prompt-only methods.
It is about building a system, not a prompt.
References
- Leng, Q., Portes, J., Havens, S., Zaharia, M. and Carbin, M. (2024) ‘Long Context RAG Performance of LLMs’. Databricks Blog, 12 August. Available at: https://www.databricks.com/blog/long-context-rag-performance-llms (Accessed: 12 July 2025).
- Hron, J. (2025) ‘Legal AI Benchmarking: Evaluating Long Context Performance for LLMs’. Thomson Reuters Innovation Blog, 14 April. Available at: https://blogs.thomsonreuters.com/en-us/innovation/legal-ai-benchmarking-evaluating-long-context-performance-for-llms/ (Accessed: 12 July 2025).
- Xu, P., Ping, W., Wu, X., McAfee, L., Zhu, C., Liu, Z., Subramanian, S., Bakhturina, E., Shoeybi, M. and Catanzaro, B. (2023) ‘Retrieval Meets Long Context Large Language Models’. arXiv preprint arXiv:2310.03025. Available at: https://arxiv.org/abs/2310.03025 (Accessed: 12 July 2025).
👥 Join the JigsawStack Community
Have questions or want to show off what you’ve built? Join the JigsawStack developer community on Discord and X/Twitter. Let’s build something amazing together!